" width="61.00000083726604px"><g d="M 19.413 0 L 21.752 0 L 21.752 9.05 C 21.752 9.696 21.228 10.221 20.582 10.221 L 20.582 10.221 C 19.936 10.221 19.411 9.696 19.411 9.05 L 19.411 0 L 19.411 0 Z M 51.238 7.848 C 51.238 6.773 52.11 5.902 53.185 5.902 C 54.26 5.902 55.131 6.773 55.131 7.848 C 55.131 8.923 54.26 9.795 53.185 9.795 C 52.11 9.795 51.238 8.923 51.238 7.848 Z M 43.244 0 L 43.244 0 L 43.244 0 L 40.939 0 L 40.939 0 L 40.939 0 L 40.939 11.7 L 35.702 5.595 L 30.903 0 L 30.903 0 L 30.903 0 L 27.95 0 L 27.95 0 L 27.95 0 L 29.753 2.132 L 29.774 2.157 L 29.774 15.316 L 32.015 15.316 L 32.015 4.784 L 40.98 15.316 L 40.98 15.314 L 41.293 15.662 L 43.244 15.662 L 43.244 13.338 L 43.244 13.338 Z M 5.823 2.282 L 9.155 2.282 L 9.155 9.221 C 9.155 9.221 9.176 13.47 5.342 13.47 C 2.471 13.47 1.152 11.91 1.152 11.91 L 0 13.88 C 1.319 15.009 3.478 15.686 5.321 15.686 C 7.982 15.686 11.416 14.003 11.416 9.28 L 11.416 0.023 L 4.819 0.023 L 5.825 2.28 Z M 25.339 9.383 C 25.339 12.011 23.621 13.447 20.584 13.447 C 17.546 13.447 15.828 12.011 15.828 9.383 L 15.828 0.023 L 13.567 0.023 L 13.567 9.383 C 13.567 13.365 16.164 15.686 20.584 15.686 C 25.004 15.686 27.601 13.367 27.601 9.383 L 27.601 2.128 L 25.339 0.023 Z M 19.413 0 L 21.752 0 L 21.752 9.05 C 21.752 9.696 21.228 10.221 20.582 10.221 L 20.582 10.221 C 19.936 10.221 19.411 9.696 19.411 9.05 L 19.411 0 L 19.411 0 Z M 51.238 7.848 C 51.238 6.773 52.11 5.902 53.185 5.902 C 54.26 5.902 55.131 6.773 55.131 7.848 C 55.131 8.923 54.26 9.795 53.185 9.795 C 52.11 9.795 51.238 8.923 51.238 7.848 Z M 53.185 15.662 C 48.876 15.662 45.369 12.155 45.369 7.846 C 45.369 3.537 48.876 0.031 53.185 0.031 C 57.494 0.031 61 3.537 61 7.846 C 61 12.155 57.494 15.662 53.185 15.662 Z M 53.185 2.617 C 50.3 2.617 47.954 4.963 47.954 7.848 C 47.954 10.733 50.3 13.079 53.185 13.079 C 56.07 13.079 58.415 10.733 58.415 7.848 C 58.415 4.963 56.07 2.617 53.185 2.617 Z" fill="transparent" height="15.686243231336453px" id="gDrTfRtn_" width="61.00000083726604px"><path d="M 0.002 0 L 2.342 0 L 2.342 9.05 C 2.342 9.696 1.817 10.221 1.171 10.221 L 1.171 10.221 C 0.525 10.221 0 9.696 0 9.05 L 0 0 L 0 0 Z" fill="rgb(244, 166, 29)" height="10.220854692083249px" id="qIdUh61VQ" transform="translate(19.411 0)" width="2.3417218924080636px"/><path d="M 0 1.947 C 0 0.872 0.872 0 1.947 0 C 3.022 0 3.893 0.872 3.893 1.947 C 3.893 3.022 3.022 3.893 1.947 3.893 C 0.872 3.893 0 3.022 0 1.947 Z" fill="rgb(244, 166, 29)" height="3.8932669775360473px" id="VQHRrXqEg" transform="translate(51.238 5.902)" width="3.8932669775360367px"/><path d="M 15.293 0 L 15.293 0 L 15.293 0 L 12.989 0 L 12.989 0 L 12.989 0 L 12.989 11.7 L 7.752 5.595 L 2.953 0 L 2.953 0 L 2.953 0 L 0 0 L 0 0 L 0 0 L 1.803 2.132 L 1.823 2.157 L 1.823 15.316 L 4.064 15.316 L 4.064 4.784 L 13.03 15.316 L 13.03 15.314 L 13.342 15.662 L 15.293 15.662 L 15.293 13.338 L 15.293 13.338 Z" fill="rgb(255, 255, 255)" height="15.6615512505427px" id="DVnvdRVWZ" transform="translate(27.95 0)" width="15.293213624232454px"/><path d="M 5.823 2.259 L 9.155 2.259 L 9.155 9.198 C 9.155 9.198 9.176 13.447 5.342 13.447 C 2.471 13.447 1.152 11.888 1.152 11.888 L 0 13.857 C 1.319 14.987 3.478 15.664 5.321 15.664 C 7.982 15.664 11.416 13.98 11.416 9.258 L 11.416 0 L 4.819 0 L 5.825 2.257 Z" fill="rgb(255, 255, 255)" height="15.663609002644995px" id="KK_XcWI1r" transform="translate(0 0.023)" width="11.416408663514794px"/><path d="M 11.772 9.361 C 11.772 11.988 10.054 13.425 7.017 13.425 C 3.98 13.425 2.261 11.988 2.261 9.361 L 2.261 0 L 0 0 L 0 9.361 C 0 13.342 2.597 15.664 7.017 15.664 C 11.437 15.664 14.034 13.345 14.034 9.361 L 14.034 2.105 L 11.772 0 Z" fill="rgb(255, 255, 255)" height="15.663609002644995px" id="mUkxlHw3M" transform="translate(13.567 0.023)" width="14.033869337629884px"/><path d="M 0.002 0 L 2.342 0 L 2.342 9.05 C 2.342 9.696 1.817 10.221 1.171 10.221 L 1.171 10.221 C 0.525 10.221 0 9.696 0 9.05 L 0 0 L 0 0 Z" fill="rgb(244, 166, 29)" height="10.220854692083249px" id="R4AFRIJi2" transform="translate(19.411 0)" width="2.3417218924080636px"/><path d="M 0 1.947 C 0 0.872 0.872 0 1.947 0 C 3.022 0 3.893 0.872 3.893 1.947 C 3.893 3.022 3.022 3.893 1.947 3.893 C 0.872 3.893 0 3.022 0 1.947 Z" fill="rgb(244, 166, 29)" height="3.8932669775360473px" id="RIYk3Rcd2" transform="translate(51.238 5.902)" width="3.8932669775360367px"/><path d="M 7.815 15.631 C 3.506 15.631 0 12.124 0 7.815 C 0 3.506 3.506 0 7.815 0 C 12.124 0 15.631 3.506 15.631 7.815 C 15.631 12.124 12.124 15.631 7.815 15.631 Z M 7.815 2.587 C 4.93 2.587 2.585 4.932 2.585 7.817 C 2.585 10.702 4.93 13.048 7.815 13.048 C 10.7 13.048 13.046 10.702 13.046 7.817 C 13.046 4.932 10.7 2.587 7.815 2.587 Z" fill="rgb(255, 255, 255)" height="15.630684968798825px" id="d7XHjCA17" transform="translate(45.369 0.031)" width="15.630684969008314px"/></g></g></svg>)
Products
CAPABILITIES
DEPLOYMENT
Integrations


STORAGE


ANALYTICS




One compute plane. Every workload.
One compute plane. Every workload.
Orion orchestrates GPU workloads, containers, VMs, and bare metal from one unified compute plane. Your team manages one system instead of five.
Orion orchestrates GPU workloads, containers, VMs, and bare metal from one unified compute plane. Your team manages one system instead of five.
The fragmentation problem.
Most teams manage separate systems for containers, VMs, and bare metal. That means three ops workflows, three billing systems, and three sets of failure points.
VMware costs are up 150% to 10×+
vSphere 7 is already out of support. vSphere 8 end of general support: October 2027. The migration window is narrowing, and every path forward involves rebuilding your infrastructure.
GPU hardware sits idle most of the time
Enterprise on-premises GPU utilization sits at 10–15%. The hardware is paid for. The capacity is there. Most environments lack the orchestration layer to actually use it.
Three clusters for three substrate types
Kubernetes for containers. VMware for VMs. Custom tooling for bare metal. Each has its own admin workflow, billing model, and failure mode. Your team manages the seams, not the work.
Provisioning measured in days, not minutes
Getting a researcher or artist a GPU workstation means a ticket, a queue, and someone from ops in the loop. That friction adds up. Orion provisions in 60 seconds, without IT involvement.
Orchestration as a Service.
One cluster for every workload type.

GPU Operator Automation
Typically 2–4× more workload density
Orion automates NVIDIA GPU operator installation and configuration. Admins choose their slicing method (MIG, vGPU, or time slicing) through a UI. No YAML. No manual node labeling. AMD and Intel GPU support available via community plugin (roadmap). End users get more capacity without knowing it exists.
GPU Operator Automation
Typically 2–4× more workload density
Orion automates NVIDIA GPU operator installation and configuration. Admins choose their slicing method (MIG, vGPU, or time slicing) through a UI. No YAML. No manual node labeling. AMD and Intel GPU support available via community plugin (roadmap). End users get more capacity without knowing it exists.
GPU Operator Automation
Typically 2–4× more workload density
Orion automates NVIDIA GPU operator installation and configuration. Admins choose their slicing method (MIG, vGPU, or time slicing) through a UI. No YAML. No manual node labeling. AMD and Intel GPU support available via community plugin (roadmap). End users get more capacity without knowing it exists.

Autoscaling
Right-node, right-size autoscaling
When demand spikes, Orion selects the right node for the job — not just the largest available. Scale up on burst, scale back when idle. No wasted capacity, no over-provisioning.
Autoscaling
Right-node, right-size autoscaling
When demand spikes, Orion selects the right node for the job — not just the largest available. Scale up on burst, scale back when idle. No wasted capacity, no over-provisioning.
Autoscaling
Right-node, right-size autoscaling
When demand spikes, Orion selects the right node for the job — not just the largest available. Scale up on burst, scale back when idle. No wasted capacity, no over-provisioning.

Load Balancing
Request-aware load balancing
Orion distributes workloads evenly across your fleet by active request count, not just CPU/memory headroom. Your cluster stays balanced without manual intervention.
Load Balancing
Request-aware load balancing
Orion distributes workloads evenly across your fleet by active request count, not just CPU/memory headroom. Your cluster stays balanced without manual intervention.
Load Balancing
Request-aware load balancing
Orion distributes workloads evenly across your fleet by active request count, not just CPU/memory headroom. Your cluster stays balanced without manual intervention.
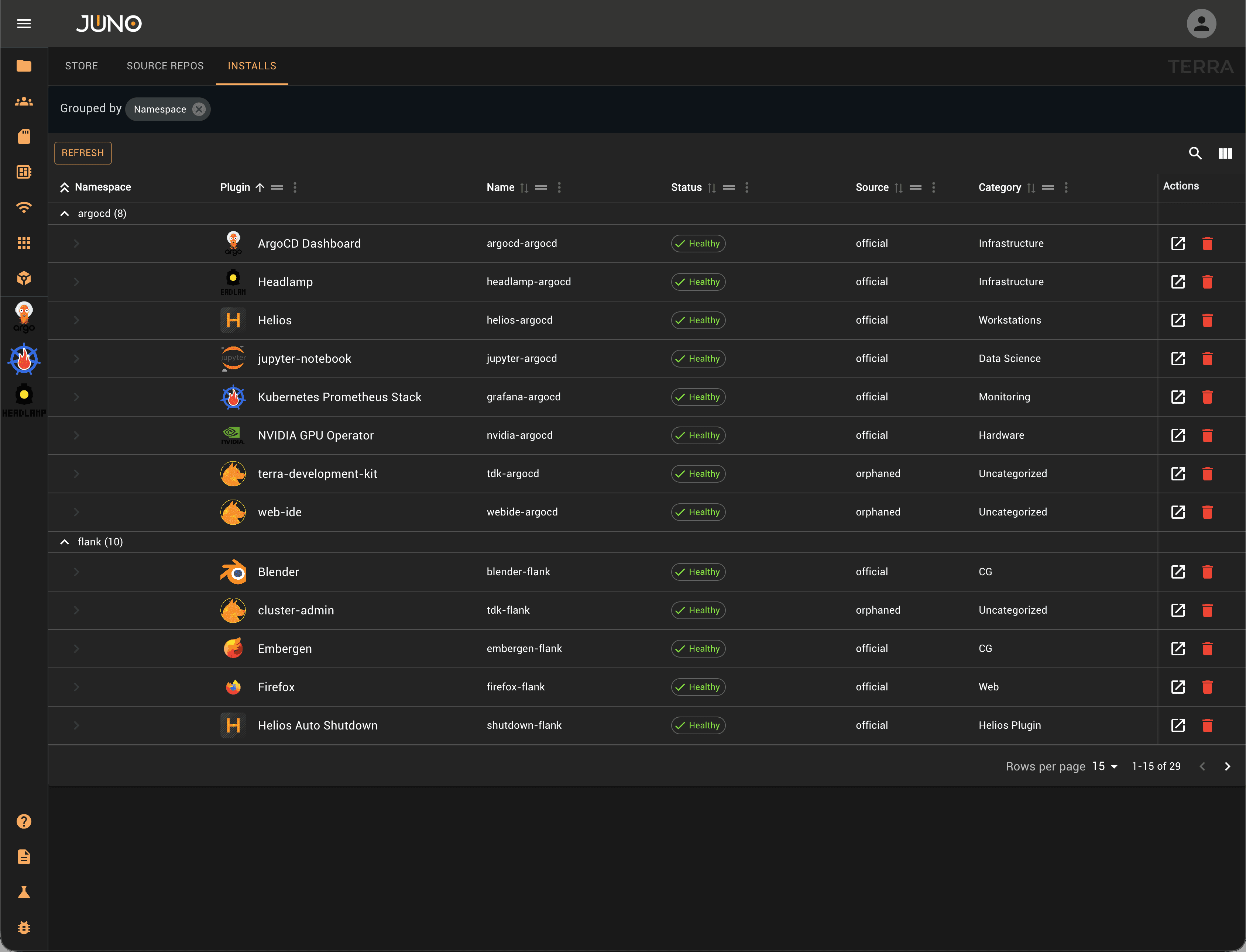
Provisioning
60-Second Provisioning
No tickets. No JIRA queues. No waiting for IT. Orion provisions containerized and virtualized workloads on demand — researchers and artists get their environment before they've finished their coffee.
Provisioning
60-Second Provisioning
No tickets. No JIRA queues. No waiting for IT. Orion provisions containerized and virtualized workloads on demand — researchers and artists get their environment before they've finished their coffee.
Provisioning
60-Second Provisioning
No tickets. No JIRA queues. No waiting for IT. Orion provisions containerized and virtualized workloads on demand — researchers and artists get their environment before they've finished their coffee.
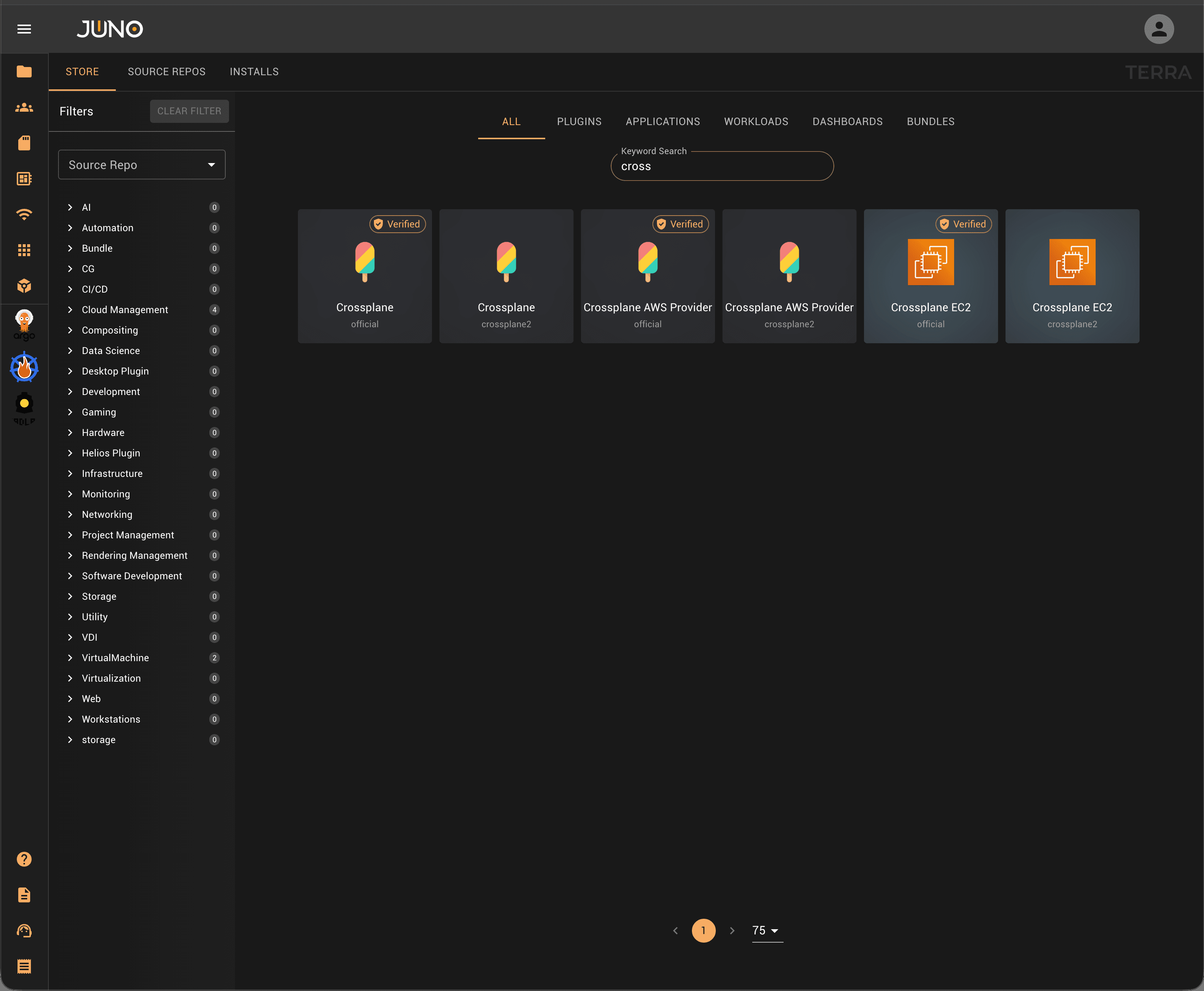
Multi-Cloud Orchestration
Crossplane: no drift, no lock-in.
Via Crossplane (available as a Terra plugin), Orion enforces your infrastructure configuration continuously. Unlike Terraform or Pulumi, which apply once and drift. Mount AWS, GCP, Azure, or on-prem as a single abstraction. Deploy the same way everywhere. If a cloud raises prices or goes down, you have a path out.
Multi-Cloud Orchestration
Crossplane: no drift, no lock-in.
Via Crossplane (available as a Terra plugin), Orion enforces your infrastructure configuration continuously. Unlike Terraform or Pulumi, which apply once and drift. Mount AWS, GCP, Azure, or on-prem as a single abstraction. Deploy the same way everywhere. If a cloud raises prices or goes down, you have a path out.
Your entire fleet, one view.
Your entire fleet, one view.
Orion sits between your infrastructure and your workloads, scheduling containers, VMs, and bare metal jobs across GPU and CPU resources with unified visibility across the whole fleet.
Orion sits between your infrastructure and your workloads, scheduling containers, VMs, and bare metal jobs across GPU and CPU resources with unified visibility across the whole fleet.






Your DevOps team defines the rules. Your users click a button. Everything between those two moments is Orion.
Customer-hosted
Your data never leaves your perimeter.
Orion deploys in your environment: on-prem, air-gapped, or hybrid. There is no cloud management plane calling home, no vendor access to your cluster, and no egress fees. For life sciences, defense, and enterprise teams where data sovereignty is non-negotiable, this is the architecture that makes Orion viable where others aren't.
No cloud management plane
Orion runs entirely within your network. No AWS account required, no Azure backbone, no external orchestration layer. Your cluster operates independently of any vendor's cloud.
Zero vendor telemetry
No phone-home. No licensing server that needs internet access. Licensing, updates, and orchestration all operate inside your perimeter. Fully air-gapped deployments are production-supported.
No egress surprises
Data stays where you put it. No egress fees, no cross-region transfer, no hidden bandwidth costs. R3D cut their AWS compute bill ~40% in part because their data stopped moving.
Terra App Store
The infrastructure app store. Powered by GitOps.
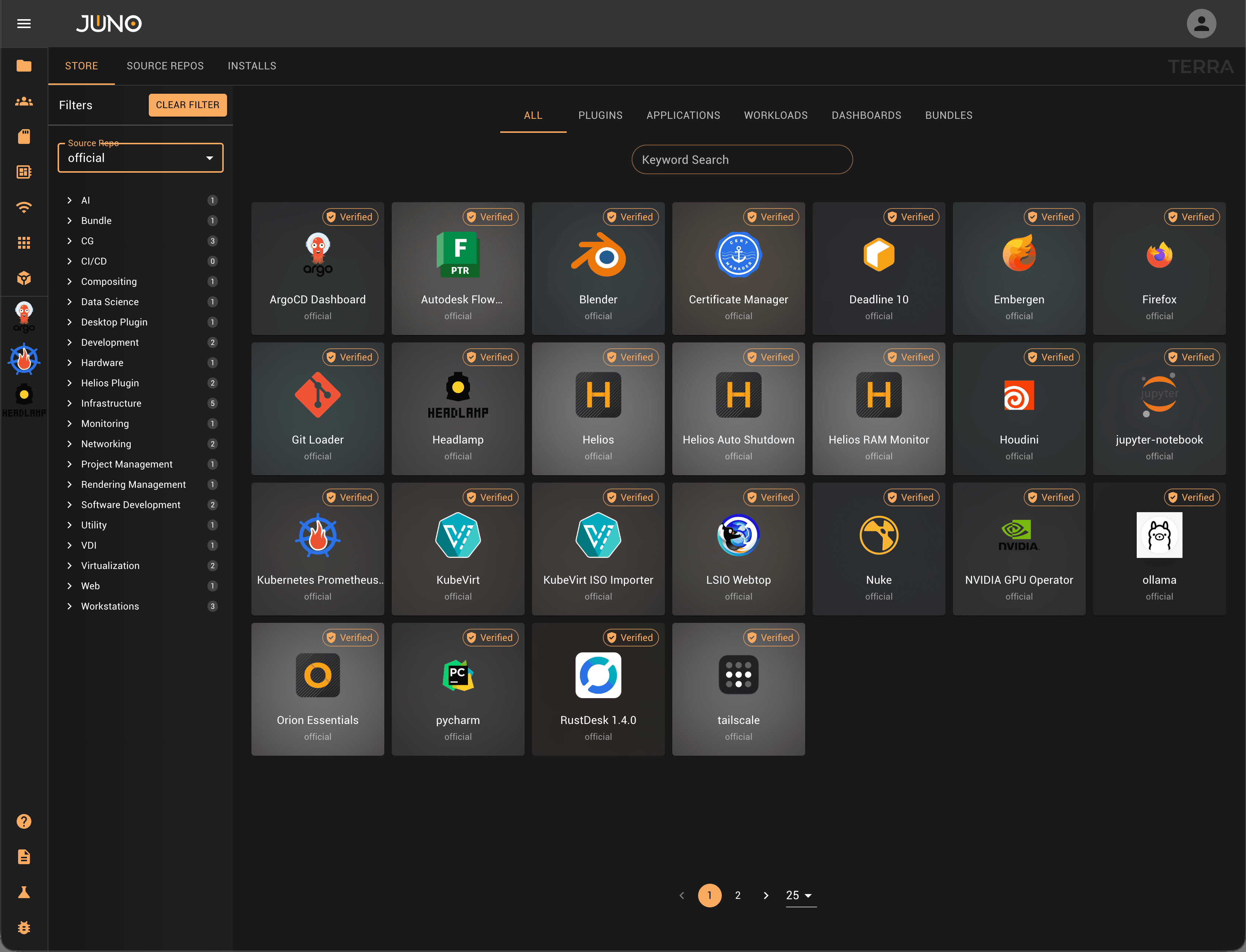
Once engineers start using Terra, Orion stops being infrastructure — it becomes the developer experience. Terra is Orion's infrastructure app store. Three plugin types cover everything your team needs.
Operators install GPU drivers, AI runtimes, and cluster tooling with opinionated defaults that cover 99% of deployments.
Template Engines define full environments — Helios containerized desktops, JupyterLab, VS Code Server, custom pipelines — delivered to any user with one click.
Network and Services plugins drop in Tailscale exit nodes, NFS provisioners, and connection brokers without touching cluster config. Fork any chart if you need to go deeper.
Terra App Store
The infrastructure app store. Powered by GitOps.
The infrastructure app store. Powered by GitOps.
Terra is Orion's infrastructure app store. Operator plugins install GPU drivers, AI runtimes, and cluster tooling with opinionated defaults that cover the vast majority of deployments. Template Engines define full environments: Helios desktops, JupyterLab, VS Code Server, custom pipelines, delivered to any user with one click. Network and Services plugins drop in Tailscale nodes, NFS provisioners, and connection brokers without touching cluster config. Fork any chart to go deeper.
Terra is Orion's infrastructure app store. Operator plugins install GPU drivers, AI runtimes, and cluster tooling with opinionated defaults that cover the vast majority of deployments. Template Engines define full environments: Helios desktops, JupyterLab, VS Code Server, custom pipelines, delivered to any user with one click. Network and Services plugins drop in Tailscale nodes, NFS provisioners, and connection brokers without touching cluster config. Fork any chart to go deeper.
Alex Hatfield
CEO & Co-Founder, Juno Innovations
"The idea was always Lego bricks. You pick the tools your team needs: GPU operators, runtimes, workload templates. Click to install, and they just work. All the hard stuff stays on our side. You just build."

Terra App Store
One-click app installs
VS Code Server, JupyterLab, DCC tools, custom pipelines — deploy production-ready environments in seconds, not hours.
Terra App Store
One-click app installs
VS Code Server, JupyterLab, DCC tools, custom pipelines — deploy production-ready environments in seconds, not hours.
Terra App Store
One-click app installs
VS Code Server, JupyterLab, DCC tools, custom pipelines — deploy production-ready environments in seconds, not hours.

Templating
Reusable Templates
Build once, deploy everywhere. Create golden-image templates for dev, staging, and production workflows that work identically across your whole team.
Templating
Reusable Templates
Build once, deploy everywhere. Create golden-image templates for dev, staging, and production workflows that work identically across your whole team.
Templating
Reusable Templates
Build once, deploy everywhere. Create golden-image templates for dev, staging, and production workflows that work identically across your whole team.
Versioning
Full Version History
Track every environment change. Roll back to any previous configuration instantly. No more 'it worked last week' debugging sessions.
Versioning
Full Version History
Track every environment change. Roll back to any previous configuration instantly. No more 'it worked last week' debugging sessions.
Versioning
Full Version History
Track every environment change. Roll back to any previous configuration instantly. No more 'it worked last week' debugging sessions.
Helios Workstations
A workstation for every user. Launched in 60 seconds.
A workstation for every user. Launched in 60 seconds.
Containerized desktop environments provisioned on demand. Users request the resources they need: GPU, RAM, applications. Helios delivers a full workstation in under 60 seconds. When the session ends, resources return to the pool. No idle machines. No assigned hardware. No IT queue.
Containerized desktop environments provisioned on demand. Users request the resources they need: GPU, RAM, applications. Helios delivers a full workstation in under 60 seconds. When the session ends, resources return to the pool. No idle machines. No assigned hardware. No IT queue.
Full desktop, zero footprint
Every Helios workstation is a containerized environment with full GPU access, persistent storage, and the tools your team already uses. VS Code, JupyterLab, Nuke, Houdini, Blender — launched from a browser, destroyed on logout.
Full desktop, zero footprint
Every Helios workstation is a containerized environment with full GPU access, persistent storage, and the tools your team already uses. VS Code, JupyterLab, Nuke, Houdini, Blender — launched from a browser, destroyed on logout.
Capacity that comes back
Traditional VDI pre-provisions fixed VMs that sit idle 70% of the time. Helios provisions on demand and releases resources when sessions end. R3D Studios doubled artist capacity on the same GPU hardware with this model.
Capacity that comes back
Traditional VDI pre-provisions fixed VMs that sit idle 70% of the time. Helios provisions on demand and releases resources when sessions end. R3D Studios doubled artist capacity on the same GPU hardware with this model.
Browser-based, anywhere
Artists and researchers connect through a browser: no VPN client, no fat installer, no IT ticket. Selkies delivers color-accurate streaming with sub-frame latency via WebRTC. Works from the office, from home, or from a hotel lobby.
Browser-based, anywhere
Artists and researchers connect through a browser: no VPN client, no fat installer, no IT ticket. Selkies delivers color-accurate streaming with sub-frame latency via WebRTC. Works from the office, from home, or from a hotel lobby.
KubeVirt
Windows and Linux VMs, orchestrated like containers.
Windows and Linux VMs, orchestrated like containers.
Windows and Linux VMs, orchestrated like containers.
Orion orchestrates Windows and Linux VMs through KubeVirt on the same Kubernetes cluster as your containers. Windows Server 2019 and 2022, GPU pass-through and vGPU slicing, live migration between nodes without downtime: all managed from the same compute plane. No separate hypervisor stack. No infrastructure consolidation project. Run Adobe Creative Suite on Windows while rendering on Linux, and deploy both with the same 60-second provisioning your containerized workloads get.
Orion orchestrates Windows and Linux VMs through KubeVirt on the same Kubernetes cluster as your containers. Windows Server 2019 and 2022, GPU pass-through and vGPU slicing, live migration between nodes without downtime: all managed from the same compute plane. No separate hypervisor stack. No infrastructure consolidation project. Run Adobe Creative Suite on Windows while rendering on Linux, and deploy both with the same 60-second provisioning your containerized workloads get.
Windows app support
Adobe Creative Suite, Autodesk, DaVinci Resolve, and more.
Windows app support
Adobe Creative Suite, Autodesk, DaVinci Resolve, and more.
Windows app support
Adobe Creative Suite, Autodesk, DaVinci Resolve, and more.
GPU pass-through and vGPU slicing
Run GPU-accelerated Windows workloads via KubeVirt.
GPU pass-through and vGPU slicing
Run GPU-accelerated Windows workloads via KubeVirt.
Helm-compatible by default
Import existing Kubernetes workload definitions, templatize them, and make them requestable by end users. No rewriting required.
Helm-compatible by default
Import existing Kubernetes workload definitions, templatize them, and make them requestable by end users. No rewriting required.
Helm-compatible by default
Import existing Kubernetes workload definitions, templatize them, and make them requestable by end users. No rewriting required.
See everything. Operate with confidence.
See everything. Operate with confidence.
Orion surfaces utilization, CPU saturation, memory pressure, job throughput, and cost-per-workload across your entire fleet in real time. Provision in minutes with reusable templates, enforce resource quotas across teams, and run on any storage layer you already own. See where you're getting value and where capacity is sitting idle.
Orion surfaces utilization, CPU saturation, memory pressure, job throughput, and cost-per-workload across your entire fleet in real time. Provision in minutes with reusable templates, enforce resource quotas across teams, and run on any storage layer you already own. See where you're getting value and where capacity is sitting idle.
Up and running fast
Provision GPU capacity in minutes with sane defaults and reusable templates. No spreadsheet archaeology, no tribal knowledge required.
Up and running fast
Provision GPU capacity in minutes with sane defaults and reusable templates. No spreadsheet archaeology, no tribal knowledge required.
Built for shared teams
Researchers, engineers, and platform teams all in one place — with resource quotas, queue management, and RBAC so nobody steps on each other.
Built for shared teams
Researchers, engineers, and platform teams all in one place — with resource quotas, queue management, and RBAC so nobody steps on each other.
No lock-in. Your infrastructure, your choice.
Orion connects through standard Kubernetes primitives. No proprietary plugins, no forced migration, no rearchitecture required. Deploy on what you already have.
No lock-in. Your infrastructure, your choice.
Orion connects through standard Kubernetes primitives. No proprietary plugins, no forced migration, no rearchitecture required. Deploy on what you already have.
Works with the storage you already have
NFS and iSCSI connect natively. Qumulo, Weka, Vast, S3, and any other CSI-compatible provider connect via standard Kubernetes CSI driver. No migration, no rearchitecture, no new storage vendor required.
Why infrastructure teams choose Orion
Why infrastructure teams choose Orion
Three capabilities no funded competitor offers simultaneously. Here's how the platforms compare.
Three capabilities no funded competitor offers simultaneously. Here's how the platforms compare.
Traditional infrastructure management
Manual GPU provisioning — hours of wait time per deployment.
10-15% average GPU utilization — paying for capacity you never use.
Siloed clusters with no unified view across your fleet.
Kubernetes complexity that requires a dedicated platform team.
VMs and containers managed by completely separate tools.
Vendor lock-in with proprietary orchestration layers.
Juno
Purpose-built for compute orchestration — containers, VMs, GPUs, and bare metal.
Typically 2–4× workload density via native GPU operator time slicing — no new hardware.
One compute plane — containers, VMs, and bare metal unified.
Fast provisioning via the Orion dashboard — no complex setup required.
Production-ready in days, not months. Kubernetes-native.
Open standards — no vendor lock-in, ever.
Traditional infrastructure management
Manual GPU provisioning — hours of wait time per deployment.
10-15% average GPU utilization — paying for capacity you never use.
Siloed clusters with no unified view across your fleet.
Kubernetes complexity that requires a dedicated platform team.
VMs and containers managed by completely separate tools.
Vendor lock-in with proprietary orchestration layers.
Purpose-built for compute orchestration — containers, VMs, GPUs, and bare metal.
Typically 2–4× workload density via native GPU operator time slicing — no new hardware.
One compute plane — containers, VMs, and bare metal unified.
Fast provisioning via the Orion dashboard — no complex setup required.
Production-ready in days, not months. Kubernetes-native.
Open standards — no vendor lock-in, ever.
Traditional infrastructure management
Manual GPU provisioning — hours of wait time per deployment.
10-15% average GPU utilization — paying for capacity you never use.
Siloed clusters with no unified view across your fleet.
Kubernetes complexity that requires a dedicated platform team.
VMs and containers managed by completely separate tools.
Vendor lock-in with proprietary orchestration layers.
Purpose-built for compute orchestration — containers, VMs, GPUs, and bare metal.
Typically 2–4× workload density via native GPU operator time slicing — no new hardware.
One compute plane — containers, VMs, and bare metal unified.
Fast provisioning via the Orion dashboard — no complex setup required.
Production-ready in days, not months. Kubernetes-native.
Open standards — no vendor lock-in, ever.
Frequently asked questions

Orion is a containerized workload platform for on-prem, cloud, or hybrid deployments with GPU time-slicing and auto-scaling.
Yes, Orion mounts your existing file shares and toolchain locations into containers
2-5 seconds with cached images, 1-3 minutes for new nodes depending on workload type.
Yes, from Raspberry Pis to enterprise-grade - anything that can run containers
No license needed for default time-slicing. GRID/vGPU licensing only required for MIG mode.
Any Kubernetes cluster - EKS, AKS, GKE, or on-premises. We're 100% cloud-agnostic.
Per user, per month with volume discounts for larger teams. We will be moving to a node and consumption based model this year.
No long-term contract required · Deploy in your environment · Up and running in under two minutes
See Orion in your environment.
Most teams are getting 10–15% GPU utilization out of hardware they've already paid for. Orion changes that without a rip-and-replace. Talk to us about your workload profile.
No long-term contract required · Deploy in your environment · Up and running in under two minutes
